
SEOを実施するとよく聞くrobots.txtファイルについて理解していますか?
検索エンジン向けに作成するファイルで、名前からしてちょっと難しそうなイメージがあるかもしれませんが、実際はかんたんに作成できます。
書き方自体はシンプルですが、その役割はとても重大で、SEOには薬にも毒にもなります。
robots.txtの書き方やルールと併せて、使う時の注意点、どんな時に使うのか、といったことを解説します。
目次
robots.txtとは
robots.txtとは、検索エンジンなどのクローラーのアクセスを制御をするための指示を記載するためのファイルです。
robots.txtファイルのルールは、Robots Exclusion Protocol (RES) (ロボット排除規約) によって定められています。
RESは、有志によって策定されたもので、公的な標準化団体は関与していないため、強制力はありません。
ルールに従うどうかは各クローラー次第であり、構文の解釈もそれぞれに異なることがあります。
と言っても、Googleやbing検索エンジンはrobots.txtをサポートしていますし、日本ではGoogleの検索システムが圧倒的なシェアを持っているので、クローラーの差異を気にする必要はほとんどないでしょう。
※Yahoo! JAPAN検索エンジンはGoogleのシステムを利用しています。
robots.txtの使い方
roobots.txtはどのような時に使うのものなのか、その目的や効果と一緒に理解しておきましょう。
特定のページやディレクトリへのクロールをブロックする
クローラーは際限なくあなたのサイトをクロールし続けているわけではなく、1回または1日あたりのボリュームを毎回調整しながらクロールしています。
そこで、クロールしてほしいページに効率よくクローラーが巡回できるように、クロール不要なページやディレクトリをブロックします。
画像を検索結果で非表示にする
画像を検索結果に出さないようにするのにrobots.txtを利用します。
SEOに詳しい人であれば「robots.txtの記述で削除できるの?」と思うことでしょう。
Webページであれば、HTMLソースにnoindexメタタグを記述することで検索結果から削除しますが、画像の場合はnoindexメタタグを記述することができませんね。
Googleのヘルプには以下のような記載があります。
robots.txt は、画像ファイルが Google 検索結果に表示されないようにします(ただし、他のページやユーザーが画像にリンクするのを防ぐことはできません)。
noindex タグを検出するためには、ページをクロール(フェッチ)する必要があるためです。しかし、robots.txt ファイルでブロックしている場合、Google はページをフェッチしません。つまり、Google にページをクロールさせて、noindex タグ(またはヘッダー)を見せる必要があるのです。〜〜 略 〜〜
ただし、この方法は画像には適用されません。画像の場合は、robots.txt を使用して検索結果から除外してください。
『Google から情報を削除する』より
クローラーのクロール頻度を調整する
クローラーが頻繁にサーバーリクエストを行い、サーバーに負荷をかけることがあります。
サーバーに負荷がかかれば、肝心のユーザーがアクセスした時に表示速度が低下するなどの悪影響が出ます。もっと悪ければサーバーダウンしてしまいますね。
robots.txtを使ってクローラーのアクセス過多を防ぐことができます。
robotx.txtの書き方
robots.txtはプレーンテキストファイルなので、一般的なテキストエディタ・アプリケーションで作成できます。
Windowsならメモ帳、Macならテキストエディットといった標準ソフトでOKです。
まずは、テキストエディタで新規テキストを開き、『robots.txt』というファイル名で保存します。『.txt』の部分は拡張子です。
文字エンコードはUTF-8で保存します。
robots.txtに記述するコマンドには次のものがあります。
- User-agent
- Disallow
- Allow
- Sitemap
- Crawl-delay
User-agent (ユーザーエージェントの指定)
どのクローラーを制御したいのかを指定します。
robots.txtでは、ユーザーエージェントの記述から始めて、その下に具体的な内容を書いていきます。
User-agent: の後にクローラー名を書きます。
クローラー名の大文字と小文字は区別されません。
全てのクローラーに指定したい時は、ワイルドカードを意味するアスタリスク (*) を記述します。
User-agent: *
#クローラーへの指示を書きます。
| ユーザーエージェント | クローラー(検索エンジン) |
|---|---|
| * | 全てのボット (AdsBot-Googleは非適用) |
| Googlebot | |
| Googlebot-Image | 画像用Googleボット |
| Googlebot-Video | 動画用Googleボット |
| Googlebot-News | ニュース用Googleボット |
| AdsBot-Google | 広告用Googleボット(PC用) |
| AdsBot-Google-Mobile | 広告用Googleボット(スマホ用) |
| bingbot msnbot |
Microsoft bing検索 |
| Baiduspider | 百度(Baidiu) |
| Yetibot | NAVER |
| Yandex | Yandex |
| Slurp | 米Yahoo |
参考:
Robots Database
Google クローラ
Disallow (クロールの拒否)
ボットのクロールを拒否する対象を指定するコマンドです。
Disallow: の後にパス (URL) を記述します。
ドメインを省き、スラッシュ (/) から始めます。
URLの大文字と小文字は区別されます。
例えば https://example.com/block.html というページのクロールを拒否したい場合は、次のようになります。
ページのブロック例
User-agent: *
Disallow: /block.html
ディレクトリをブロックしたい時は、パスの末尾にスラッシュ (/) を書きます。
ディレクトリ以下のページ全てのクロールを拒否します。
ディレクトリのブロック例
User-agent: *
Disallow: /no-crawl-directory/
DIsallow: の後にスラッシュ (/) のみを記述するとサイトの全ページをブロックします。
全ページのブロック
User-agent: *
Disallow: /
Disallow: の後に何も書かないと、全ページのアクセスを許可します。
つまり、一切ブロックしない状態です。
またはDisallow自体を書かなくても(User-agentの記載のみ)同じ意味です。
全ページのアクセス許可
User-agent: *
Disallow:
Allow (クロールの許可)
クロールを許可する対象を指定します。
URLの大文字と小文字は区別されます。
Disallowでディレクトリごとブロックしたものの、そのディレクトリ内の特定のページだけはクロールしてほしい、というような時に使います。
ブロックしたディレクトリ内の特定のページのみクロールを許可する記述例User-agent: *
Disallow: /no-crawl-directory/
Allow: /no-crawl-directory/no-block.html
Sitemap (検索エンジン用サイトマップの通知)
robots.txt では、クローラーのアクセス制御の他、検索エンジン用のサイトマップの場所を伝えることができます。
Sitemap: の後にサイトマップの絶対パス (完全なURL ) を記述します。
Sitemap: https://example.com/sitemap.xmlCrawl-delay (クロール頻度の調整)
クロール頻度の調整には Crawl-delay: コマンドを使います。
「サーバーリクエストをしてから次のリクエストをするまで少なくとも◯秒は空ける」という指示で、クロールの最短の間隔を数値で指定します。
数値の単位は秒であることが多いですが、ボットによって異なり、分単位の場合もあります。
User-agent: bingbot
Crawl-delay: 5ちなみに、GoogleはCrawl-delayをサポートしていません。
代わりに、Googleサーチコンソールの[サイト設定]→[クロール速度]で変更します。
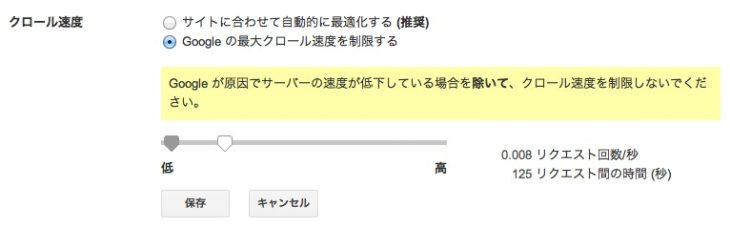
ただし、クロール頻度の調整は安易に行わない方がよいです。
クローラーからのアクセスがサイトに大きな負荷をかけている時のみ利用します。
参考:
【Crawl-delay】 検索エンジンクローラーの巡回頻度調節
Googlebot のクロール頻度の変更
コメントアウト
robots.txt内に、注意書きメモ等のコメントを残しておくことができます。
コメントアウトの記号は # です。
クローラーには、#以降その行の最後までのテキストが無視されます。
User-agent: *
#この一行は全てコメントです。
Disallow: /no-crawl-directory/
Allow: /no-crawl-directory/no-block.html #行末までコメントです。パターンマッチ (正規表現のような指定)
robots.txtでは、条件一致によるパスの指定ができます。
利用できるのはアスタリスク (*) と ダラス ($) の2つの記号です。
アスタリスク (*) はワイルドカードを意味し、0個以上の有効な文字を示します。
ダラス ($) は「〇〇で終わる」と言う意味で、末尾の文字を指定します。
パターンマッチ利用例User-agent: *
#「web」と「web〜」というディレクトリをブロック
Disallow: /web*/
#「.php」で終わるURLをブロック
Disallow: /*.php$
画像検索から削除するための記述方法
画像検索に表示されないようにするには、ユーザーエージェントに画像検索用のGoogleボットを指定してパスを入力します。
記述ルールはページのブロックと全く同じです。
画像全てを検索から削除
User-agent: Googlebot-Image
Disallow: /
ディレクトリ内の画像を検索から削除
User-agent: Googlebot-Image
Disallow: /images/
特定の画像を検索から削除
User-agent: Googlebot-Image
Disallow: /images/nocrawl-image.jpg
画像の種類(拡張子)ごとに検索から削除
User-agent: Googlebot-image
Disallow: /*.jpg$
Disallow: /*.gif$
Disallow: /*.png$
すでにインデックスされている画像が検索から消えるまでには、少し時間がかかります。
緊急で画像を削除したい時は、robots.txtの記述に加え、GoogleサーチコンソールのURL削除ツールを併用します。
https://junzou-marketing.com/url-removal-tool
URL一致の判定ルール
DisallowとAllowに記述したURLは前方一致で判定されます。
前方一致とは「〇〇で始まる場合は一致する」という判定方法です。
例えば「seo」というページへのクロールをブロックする目的で Disallow: /seo とパスを記述したとします。
もし「seo-up」という他のページが存在していた場合、同様にクロールをブロックしてしまうことになります。
完全一致ではないので注意してください。
パスの一致・不一致の例 パス 一致 不一致 /fish
/fish*/fish
/fish.html
/fish/salmon.html
/fishheads
/fishheads/yummy.html
/fish.php?id=anything/Fish.asp
/catfish
/?id=fish/fish/ /fish/
/fish/?id=anything
/fish/salmon.htm/fish
/fish.html
/Fish/Salmon.asp/*.php /filename.php
/folder/filename.php
/folder/filename.php?parameters
/folder/any.php.file.html
/filename.php//
/windows.PHP/*.php$ /filename.php
/folder/filename.php/filename.php?parameters
/filename.php/
/filename.php5
/windows.PHP/fish*.php /fish.php
/fishheads/catfish.php?parameters/Fish.PHP
『Robots.txt の仕様 -pathの一致の例-』より抜粋して引用
重複する内容の優先順位
robots.txtでは、より具体的で限定されている記述ほど優先されます。
記述の順番は関係ありません。
「/directory/」よりも「/directory/page」が優先、
「/cont」よりも「/content」の方が優先されるといった具合です。
DisallowとAllowの指定が同一である場合はAllowの指定が優先されます。
User-agentはアスタリスク (*) よりも、具体的な個別のユーザーエージェントに対しての記述が優先されます。
ボットのタイプが多くあるGoogleも同様です。
googlebotよりもgooglebot-imageの方が限定しているので優先されます。
ユーザーエージェントのフィールドグループ
ユーザーエージェントは複数記述できます。
複数のユーザーエージェントが存在する時は、各ユーザーエージェントに向けた記述のみが適用され、他のユーザーエージェント向けに書かれた記述は無視されます。
これは、ユーザーエージェントがそれぞれ独立したフィールドグループを形成するためです。
例えば、User-agent: * と User-agent: googlebot の記述がある場合、Googleボットは、User-agent: googlebot 向けに記述された内容だけに従います。
User-agent: * の記述が最初に適用され、User-agent: googlebot の内容でさらに上書きされる、とはならないので注意してください。
User-agent: *
#全てのクローラーに指示する内容を書きます。
User-agent: googlebot
#googlebotに指示する内容を書きます。
#googlebotはワイルドカード(*)向けの指示を無視します。
User-agent: googlebot-image
#googlebot-imageに指示する内容を書きます。
#googlebot-imageはワイルドカード(*)とgooglebot向けの指示を無視します。robots.txtの置き場所
robots.txtファイルはFTPソフト等を使って、ドメイン直下であるルートディレクトリにアップロードします。
ルートディレクトリに配置しないと正しく機能しません。
サブドメインにはそれぞれのルートディレクトリにrobots.txtを設置します。
robots.txtの設置は必須ではないので、もしクロールの制御が不要なら、ファイルはなくてもかまいません。または全てのアクセスを許可するファイルを設置しておいてもかまいません。
User-agent: *
Disallow:
Sitemap: https://example.com/sitemap.xmlrobots.txtの編集・更新・解除
robots.txtファイルの編集・更新は、ファイルの修正をして再度サーバーにアップして上書きすればOKです。
クローラーを制御するファイルなだけに、記述に間違いがあるとSEOに大きなダメージを与えかねません。
Googleサーチコンソールのrobots.txt テスターを利用すると、クロール動作を確認しながら編集できます。
クロールを拒否していたURLを再度クロールさせるよう修正した場合は、robots.txtファイル更新完了後に、サーチコンソールのFetch as Googleで該当ページへのクロールをリクエストしておくとよいでしょう。
クロールまたはインデックス処理を早めることができます。
robots.txtを書く時のその他の注意点
robots.txtに関してのその他の理解しておくべきことをまとめます。
CSSやJavaScriptをブロックしない
現在のGoogleボットは、私たちユーザーがページを見るのと同じようにページをレンダリングします。
ですので、ページを生成するのに必要なCSSやJavaScriptなどのリソースファイルのクロールをブロックしないようにしましょう。
Googleボットにどのようにページが見えているのかはFetch as Googleのレンダリング機能を使って確認できます。
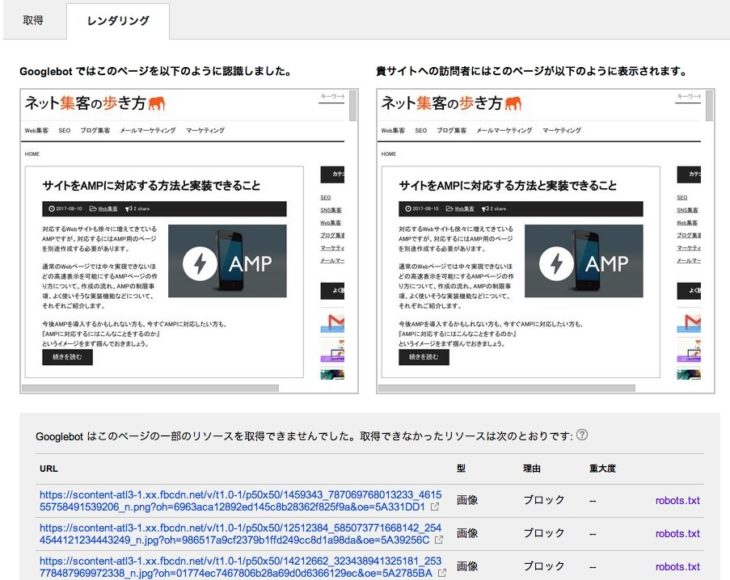
外部リンク経由でのクロールはブロックできない
robots.txt でブロックしているページに対して外部のサイトからリンクが貼られている場合は、リンクを辿ってページがクロールされることがあります。
そして、クロールされた結果、インデックス処理されて検索結果に表示されることもあります。
残念ながら、robots.txtで100%クロールを拒否することはできません。
ページのインデックス削除はできない
robots.txtはクローラーのアクセスを制御するだけであり、検索エンジンのインデックス登録を防ぐまではできません。
インデックスの拒否や削除には、noindexメタタグを使います。
詳しい利用方法は『noindexの使い方』の解説ページをご覧ください。
robots.txtファイルはクロール最適化、noindexタグはインデックス最適化で、それぞれの仕組みと役割の違いを混同しないようにしましょう。
robots.txtでセキュリティ対策はできない
クロールしてほしくないページの中には、Web上で一般公開するとまずいページやごく限られた人のみに見てほしいページなどもあるでしょう。
これらのページへのクロールをいくらブロックしたところで、robots.txtファイルそのものは見ることができることに注意してください。
例えば、次のような記述があったらどうでしょうか。
User-agent: *
Disallow: /private-folder/アクセスを拒否している「private-folder」は、いかにも個人情報類が入っている感じがしますね。
これを振る舞いの良くないボットや悪意のあるユーザーに見られたら危険ですし、ヒントすら与えてしまっています。
セキュリティ上の懸念があるURLへのパスはrobots.txtに記述せず、必ずベーシック認証などのパスワード保護を行うようにしましょう。
robots.txtでセキュリティ対策はできません。
コメントをどうぞ