
『検索エンジンがどんな仕組みでWebサイトの情報収集をしているのだろう?』と考えたことはありますか? それとも『検索に表示されているのだからそんなの気にしたことない』ですか?
いかにして検索エンジンはWeb上の情報を集めているのか?
実はSEOに直結する重要な話です。
クロールと呼ばれる検索エンジンの仕組みについて理解しておきましょう。
目次
クロール(クローリング)とは

クロールとは、GoogleのロボットがWebサイトを巡回してWebページの情報を収集していくことです。
ホームページ、ポータルサイト、ニュースサイト、コミュニティサイト、ブログ、などなど、ネット上には至る所にリンクが張り巡らされていますが、検索エンジンのロボットは、Web上のリンクを介して様々なWebページをクロールしていきます。
このように、日々Webページの情報を収集しているのが検索エンジンが行っているクロールです。
クローラー、別名スパイダー
クロールをするロボットをクローラーと呼びますが、別名スパイダーとも言われます。スパイダーはクモのことですよね。
なぜスパイダーと呼ばれるのかというと、これはWebと言う言葉に由来します。
正式名は World Wide Web ですね。URLに使われている 「www」も World Wide Web を指しています。
Webという英単語はそもそも「クモの巣」や「クモの巣状のもの」のことを意味します。
世界中に張り巡らされたクモの巣状のもの、つまりリンクによって繋がっている世界がインターネットであり、そこをクロールしているから、スパイダーというわけです。
インデックスとランキング

インデックスは直訳すると「索引」と言う意味ですよね。
検索エンジンのロボットがWebサイトをクロールした後、そのデータを処理してGoogleのデータベースに登録していきます。これをインデックスまたはインデクシングと言います。
ユーザーがキーワードを入力して検索した際には、インデックスされたWebページの中から、 200を超えるランキングアルゴリズムに基づいて検索結果が返されます。
結果が返されるまで、検索キーワードは世界中のさまざまなデータセンターを経由するので、平均で 2,400 キロメートルもの旅をすることになります。その速度は毎時 10 億キロメートルの光速並みです。
『検索の仕組み』より

検索エンジンの仕組みについては、Googleが公開しているインフォグラフィックや解説動画がわかりやすいので、一度見てみましょう。動画は日本語字幕付きで見ることができます。(表示されなければ字幕ボタンをクリックしてください。)
ディレクトリ型検索エンジンとロボット型検索エンジン
余談ですが、検索エンジンにはディレクトリ型検索エンジンとロボット型検索エンジンがあるのをご存知ですか?
ディレクトリ型検索エンジンは、人が目視をしてWebサイトを登録していくタイプのもので、Yahoo!カテゴリなどが該当します。
ロボット型検索エンジンは、人による審査がなく、ロボットが自動でサイトを登録していくタイプのもので、Googleはロボット型です。
ディレクトリ型検索エンジンは、人が審査するので、一定の質を持ったWebサイトだけが登録されるというメリットがある一方、登録できる数には限界があります。
ロボット型検索エンジンは、バンバン登録していくことができる反面、ページの質を担保することが難しいです。だからこそ、ロボット型のGoogleはアルゴリズムを改善し続けています。
2017年の3月には、世界有数のディレクトリ型検索エンジン dmoz が閉鎖されました。日々増え続けているWebサイトやページの状況を考えると、ディレクトリ型検索エンジンでは限界があるのも仕方のないことかもしれませんね。
Googleのクロールを促進する方法

検索エンジンにインデックスしてもらうにはクロールしてもらう必要があります。
より確実にクロールしてもらうために、次のような方法があります。
サイトマップファイルを送信する
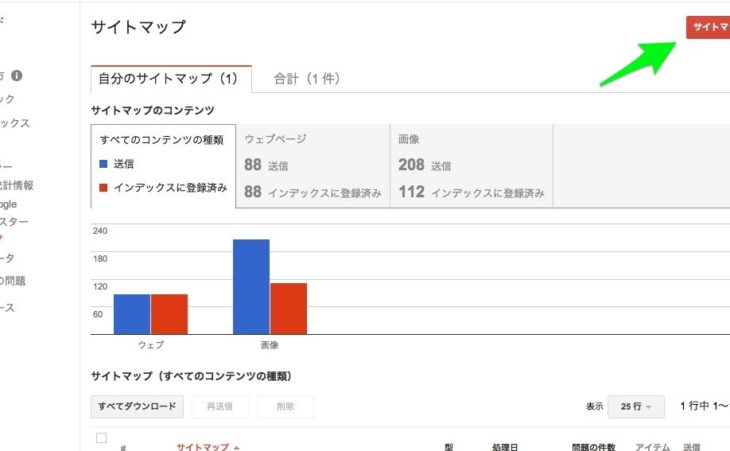
検索エンジンに読み取ってもらうためのサイトマップを作成し、Google Search Console から送信します。
Microsoftの検索エンジン Bing が提供している Bing Web マスターツール でもサイトマップを送信することができます。
Fetch as Google でクロールを依頼する
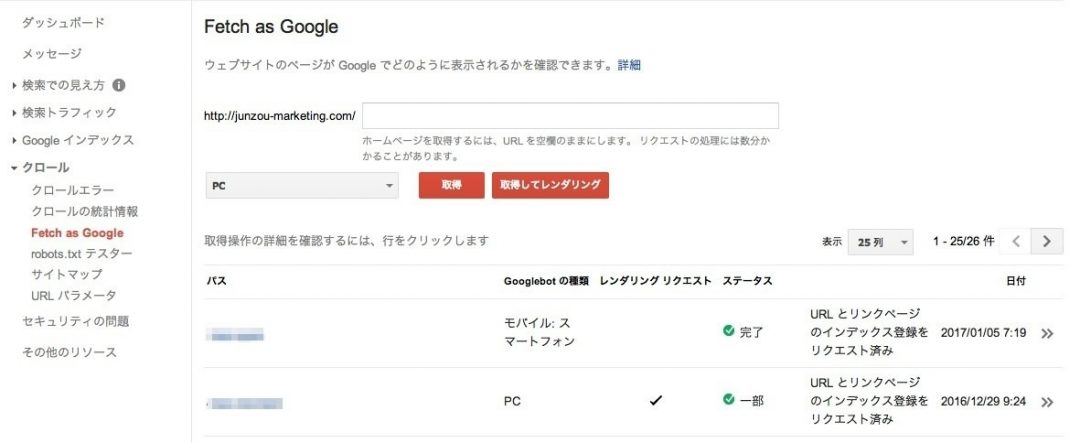
Fetch as Google を使えば、クローラーにサイトを訪問してもらえるように依頼をすることができます。
ある程度の運用実績があるサイトであれば、Fetch as Google を利用しなくてもクローラーは訪れてくれますが、運用歴の浅い新規サイトなどは Fetch as Google を活用しましょう。
リンクを送る
クローラーはリンクを辿ってサイトを訪れるので、被リンクはサイト訪問の重要なきっかけになります。
特に新規サイトの場合は、どこからもリンクを受けていない状態なので、他のサイトからリンクを送れないか考えても良いでしょう。
被リンクを送る方法の1つは、既にある自社の別サイトやグループサイトからリンクを送ってもらう方法です。
もう1つは、Webサイトを登録できる中小検索エンジンや各種ポータルサイト、プレスリリースなどからリンクを送る方法です。
ただし、検索順位を上げるための被リンク獲得が目的ではありませんので、関連性のあるいくつかのサイトからリンクを送るくらいでかまいません。固執してやり過ぎるとかえってスパムにもなりかねません。
定期的に更新をする
Googleのクロールを促す最善の方法の1つは、コンテンツを追加していくことです。
クローラーは新しい情報、修正された情報をチェックしているので、きちんと運用していくことがGoogleへのアピールになります。
それから、質にもよりますがコンテンツは多い方が、単純に被リンクがつく機会も増えていきますよね。
人為的にクロールを促すことはできますが、クローラーの巡回頻度そのものを上げるには、コンテンツを追加したり、それに伴ってナチュラルリンクが増えていくことが重要です。
ping送信をする
ページを追加・更新した時は、ping送信を行うと、いち早く更新情報を通知することができ、クロールやインデックスを促進することができます。
更新情報サービスは、ブログを更新したことをお知らせするのに利用できるツールです。WordPress は投稿を作成・更新する度にXML-RPC ping を送信することによって、ブログが更新されたことを人気のある更新情報サービスに自動的に通知します。
更新情報サービスは順番にこうした ping を処理し、独自のインデックスを更新します。
これにより、読者はGoogle ブログ検索や Yahoo! ブログ検索のようなサイトからあなたの最新の投稿を発見できます。
出典: 更新通知サービス(WordPress Codex 日本語版 より)
WordPressであれば標準でping送信をしてくれますし、pingを送信してくれるサービスもあります。
PINGZONEPing太郎- PINGOO!
robots.txt で無駄なクロールを回避する
robots.txt はクローラーを制御するためのファイルで、クローラーをブロックすることができます。ディレクトリ単位かページ単位でクロールを拒否することができます。
必要のないページをクロールさせないことで、クロールすべきなページにリソースを回しましょう。
名前の通り、拡張子が「.txt」のプレーンテキストファイルで作成します。Windowsのメモ帳やMac のテキストエディットなどで作成できます。
robots.txt に Disallow でディレクトリまたは単一ページを指定します。
ディレクトリを指定すると、その配下にあるページは全てクロールされなくなるので、ディレクトリ内の特定のページだけクロールさせたい場合は Allow を指定をしてクロールを許可します。
User-Agent: * Disallow: http://hogehoge.com/directry/ Allow: http://hogehoge.com/directry/index-page.html
User-Agent では、クローラーの種類を指定します。
* は全てのクローラーを表します。ワイルドカードの意味ですね。
Googleのクローラーであれば Googlebot、Microsoftのクローラーなら msnbot と言った具合です。特別な理由がなければ * を指定します。
robots.txt によるクロール制御の性質
robots.txt によってクロールを拒否した場合、クローラーはそのページには訪れません。
一度インデックスされてしまったページに対しては robots.txt でブロックをしても、クロールされなくなるだけであって、インデックスが削除されるわけではありません。
通常のWebページのインデックスを最適化するには、robots.txt ではなく noindex や canonical で対応します。
重 要: noindex メタタグを有効にするには、robots.txt ファイルでページをブロックしないでください。ページが robots.txt ファイルでブロックされると、クローラは noindex タグを認識しません。そのため、たとえば他のページからリンクされていると、ページは検索結果に引き続き表示される可能性があります。
Search Console ヘルプ『メタタグを使用して検索インデックス登録をブロックする』より

Webサイトの構造を最適化してクローラビリティを高める方法

Googleにクロールしてもらう上で、もう1つ重要なのが、クローラビリティです。
クローラビリティとは、クロールのしやすさのことです。
クローラーにとってクロールしやすければ、それだけ情報をきちんと読み取ってくれることになります。クロールやインデックスの目的である検索順位に影響するのがクローラビリティです。
内部リンクの構造を最適化する
Webサイト内のリンク構造が適切か確認をしましょう。
クローラーはリンクを辿ってページにアクセスするので、階層の深いページや何クリックもしなければアクセスできないページなどは、クローラビリティが悪いと言えます。
Webサイトの規模やボリュームによって、クローラビリティの定義は変わってきますが、できるだけアクセスが容易にできるように設計をします。
リンク構造については、クローラビリティだけでなく、ユーザービリティの観点からも重要です。前提として、ユーザーがアクセスしづらいページはクローラーにもアクセスしづらいページと考えておきましょう。
アンカーテキストに使う言葉にも注意しましょう。
コンテンツをカテゴリーで分ける(ディレクトリ構造の最適化)
リンク構造とも共通しますが、Webサイト内のページを全て一緒くたに扱うのではなく、カテゴリー分けをすると、テーマ、ジャンル、構成、 内容、といったことが検索エンジンに伝わやすくなります。
コンテンツや情報をどう分類するのかは、パンくずリストを考えると理解しやすいです。
シンプルな構造であれば、
下層ページ(個別ページ)< 属するカテゴリー < トップページ
というように階層が上がっていきます。
実際、ユーザーもクローラーも、どのページからサイトに訪れるのかは一定ではありませんし、検索結果に表示されるページは全て入り口になります。
パンくずリストから、サイト構成やページの上下関係を理解することができるわけですね。
サイトマップページを用意する
サイトマップのページを用意しておくと、サイト内にあるページを一覧にすることができますね。
特に、サイトの規模が大きくなるほど、サイトマップページの重要性も高まります。
クローラーだけでなく、ユーザーもサイトマップページを手がかりにすることがあります。
少しでもサイトが複雑と感じるなら、サイトマップページを用意しておきしょう。
いぜれにせよ、あって困るものではありません。
Webサイトのレスポンスを改善してクローラビリティを高める方法

レスポンスとは、Webサイトの読み込み時間(表示速度)のことです。
クローラーのリソースは限られているので、Webサイトにエラーが出ていたり、レスポンスが悪かったりすると、充分にクロールされないまま離脱されてしまいます。
重たいサイトはユーザーをイライラさせますが、クローラーをもイライラさせてしまうというわけです。
Webページのサイズが大きければ、当然ながら読み込みにも時間がかかるので改善を検討しましょう。SEOでも表示速度は重要視されているものの1つですね。
画像を圧縮する
読み込みに時間が多くかかるものの筆頭は画像です。なので、画像の軽量化をすることでパフォーマンスを改善していきます。
compressor、jpegmini、tinyPNG などの劣化を抑えて画像を圧縮してくれるツールを利用しましょう。
読み込みファイルを少なくする
JavaScriptライブラリやプラグインの読み込みは、便利な反面、サイトをどんどん重たくしていきます。プログラムによってWebサイトが重たくなってしまうケースは結構あります。
わざわざ別ファイルを読み込まなくても実装できるものであれば、コードを直接記述したり、より軽量な代替プラグインを利用するといったことができます。
特にWordPressを利用している場合、知識のない人でもプラグインを導入することで、様々な機能を簡単に実装できてしまうので、深く考えずにプラグインを足していくとレスポンスを悪化させてしまいます。
無駄なソースコードを削除する
ソースファイルから余分な記述や改行を削除して、ファイルをスリム化する方法もあります。微々たる改善になるかもしれませんが、少しでもサイズを軽くしておくという意味では、やっておいても良いでしょう。
サーバー環境を見直す

サーバー環境は、Webサイトのパフォーマンスに大きく影響します。
いわゆる格安の共用サーバーに多いのが、アクセスが集中した時にその負荷に耐えられずにサーバーが落ちてしまうケースです。
何がまずいって、サーバーの問題はこちらでは気づきにくいことが多い点です。気付いた段階では既に多くの機会損失を招いていたということが充分に起こり得ます。
単に料金だけで比較せず、回線の太い安定したサーバー環境を用意しておくことも大切です。
クロールに関するまとめ
クロール最適化についてまとめると、
- クロールされなければインデックスされないし、インデックスされなければ検索結果にも表示されない
- クローラーにとって内部・外部ともにリンクが重要
- クローラビリティを意識したWebサイトの最適化を行う
- クローラーに親切なサイトはユーザーにも親切なサイトである
- コンテンツの更新や被リンク増加がクロールを呼び込む
検索エンジンとクロールの仕組みを理解してSEOを強くしていきましょう。
コメントをどうぞ